研究简介
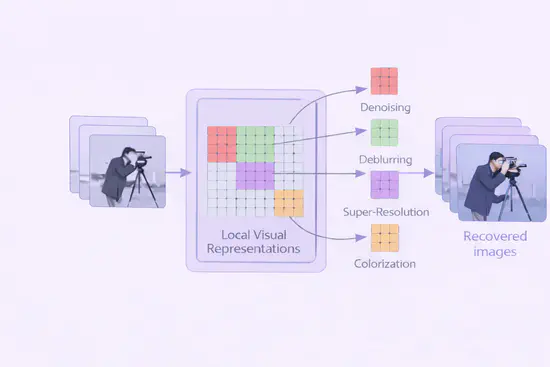
底层视觉处理
聚焦图像与视频的去噪、超分、修复等低层质量提升技术。面向复杂真实场景的退化问题,构建从像素级到特征级的完整修复体系。致力于为高层视觉任务提供清晰、稳定的高质量视觉输入,广泛支撑安防、医疗及融媒体等领域的画质优化需求。
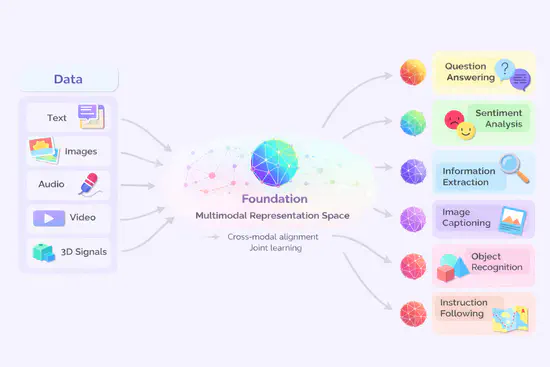
多模态预训练
研究图文、音视频等多模态异构数据的联合表征学习与大规模预训练。探索跨模态语义对齐与融合,构建统一表征空间。旨在打造通用多模态基础模型,为跨模态检索、内容生成及开放域理解等复杂任务提供统一基座与高效迁移能力。
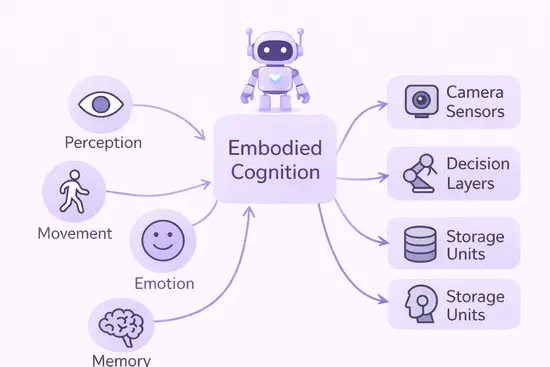
具身智能
以“感知—认知—决策—执行”闭环为核心,探究智能体在多环境中的视觉感知、行为规划与控制交互机制。融合多模态反馈与强化学习,赋予智能体自主场景理解与动态环境适应能力,推动其在机器人、自动驾驶、智能制造等场景的落地应用。
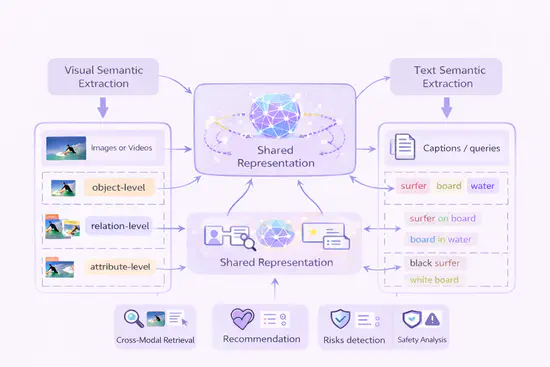
跨模态检索与内容安全
聚焦跨模态检索、风险检测与安全分析,构建图文与视频的共享语义空间,实现细粒度跨模态对齐与匹配。研究大规模数据的高效索引及内容风控机制,解决信息孤岛问题,为内容平台、搜索引擎及安全监管提供坚实的技术支撑。
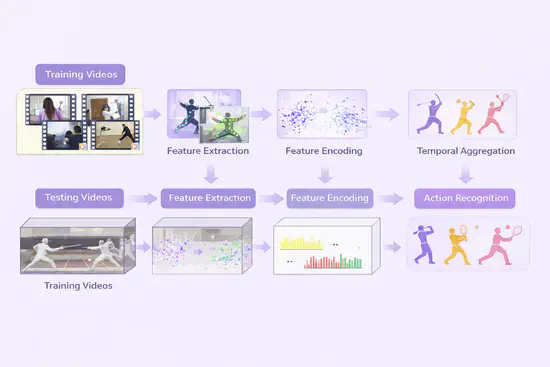
视频内容理解
深耕行为检测、识别、动作分割及事件解析等视频核心任务。面向复杂背景与长时序视频挑战,研究时空特征提取与行为语义推理方法。实现从单行为识别到复杂事件链理解的突破,广泛应用于安防分析、短视频理解、人机交互等场景。
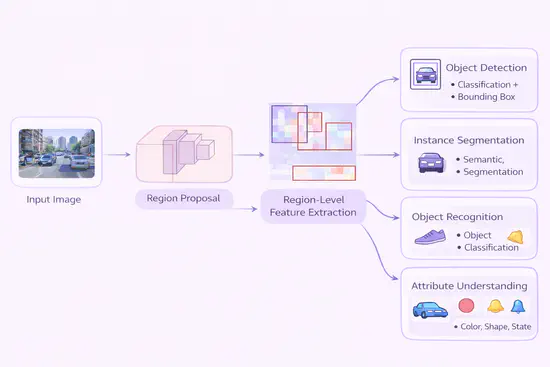
图像内容分析
围绕目标检测、分割、分类及细粒度识别等中高层视觉任务,构建精准建模框架,实现目标定位、属性解析与关系推理。致力于攻克小样本、复杂遮挡等实际难点,提升模型泛化性,全面支撑智慧城市、工业质检、内容审核等应用。
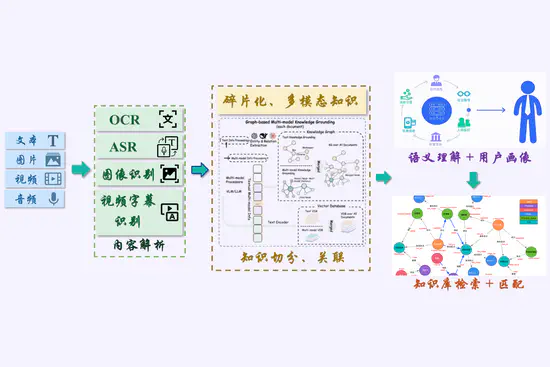
知识增强建模与应用
围绕多源知识的获取、融合与更新,研究面向复杂推理的知识图谱构建与增强范式。打通图文音多源信息提取链路,探索知识与数据双驱动的学习框架。旨在提升模型在推理生成中的可解释性与泛化能力,推动智能问答、行业大模型等场景的落地。